javaEE总结
一. Web 服务器和HTTP 协议
1.Web服务器
常见的web服务器
(1)Apache。Apache仍然是世界上⽤的最多的Web服务器,市场占有率达60%左右,可以运⾏在所有的Unix、windows、Linux平台上,使⽤PHP语⾔开发Web⽹站通常需要部署到Apache服务器。
(2) IIS。全程为Internet Information Services (IIS),由微软公司开发,也是目前最流⾏的Web服务器产品之 ⼀。IIS提供了⼀个图形界⾯的管理⼯具 ,称为Internet服务,可⽤于监视配置和控制Internet服务,⽀持asp 、sp.net等多种开发语⾔。
(3) Nginx,发⾳为「engine X」,是⼀个基于异步框架的⾼性能Web服务器,通常⽤作反向代理、负载均衡器和 HTTP缓存。Nginx由俄罗斯程序员伊⼽爾·賽索耶夫 (Игорь Сысоев)于2004开发发布,2019年被F5⽹络公司以 6.7亿美元收购,Nginx在⾼并发下能保持低资源低消耗⾼性能,⽬前是⽹络中应⽤⼴泛的Web服务器之⼀。
(4) Apache Tomcat,是⼀个⾯向中⼩型系统的Web服务器,是由Apache软件基⾦会属下Jakarta项⽬ 开发的 Servlet 容器,按照Sun Microsystems 提供的技术规范,实现了对Servlet和JavaServer Page(JSP)的支持。Tomcat往往作为Java Web开发初学者常⽤的服务器
web服务器工作原理
Web也称为万维⽹,World Wide Web,是指通过互联⽹访问的,由许多相互链接的HTML⻚⾯组成的⼀个⽹络 系统。Web服务器通常则指提供⽹站服务的⼀种运⾏在后台的应⽤程序。
web服务器和web应用的关系
**(from 网络)**Web服务器实现了HTTP协议的服务器,监听端口,接受客户端建立连接的请求,捐接收数据,并把接收到的HTTP请求通过类似CGI,WSGI,Servlet的接口交给应用程序处理,而应用程序处理后的输出交给 Web服务器,由Web服务器通过连接发送给客户端
**(from pdf)**Web系统通常包含前端和后端两部分:(1)前端由浏览器组成, 负责解析HTML⻚⾯的代码以及运⾏javascript脚本程序,完成⻚⾯渲染;(2)后端则负责处理前端发送的Http请 求,将数据或者⽹⻚及其资源⽂件发回给前端。
2.tomcat 服务器
默认端口号8080
conf/server.xml修改端口号
1 | <!-- 配置tomcat服务器端⼝号,默认为8080 --> |
tomcat服务器项目的部署的两种方式
1.编译好的项目文件复制到webapps目录下
2.将项目打包成war压缩文件, 复制到webapps目录
3.HTTP协议(超文本传输协议)
http基于TCP/IP协议,传输层基于可靠的TCP协议,默认端口号 80
可以⽤来传输HTML⽂件、图⽚⽂件和查询结果等。
https 默认端口号443
HTTP、HTML、HTTPS的区别和联系
HTTP协议被用于在Web浏览器和网站服务器之间传递信息。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此HTTP协议不适合传输一些敏感信息,比如信用卡号、密码等。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS。为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTPS和HTTP的区别主要为以下四点:
1.https协议需要到ca申请证书,一般免费证书很少,需要交费。
2.http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
3.http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4.http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络,比http协议安全。
HTML是页面描述语言
4.HTTP的报文类型:请求报文 应答(响应)报文
HTTP报文结构:头部和主体
HTTP 协议是以 ASCII 码传输,建⽴在 TCP/IP 协议之上的应⽤层规范。规范把 HTTP 请求分为三个部分:状态 ⾏、请求头、消息主体。
1 | <method> <request-URL> <version> |
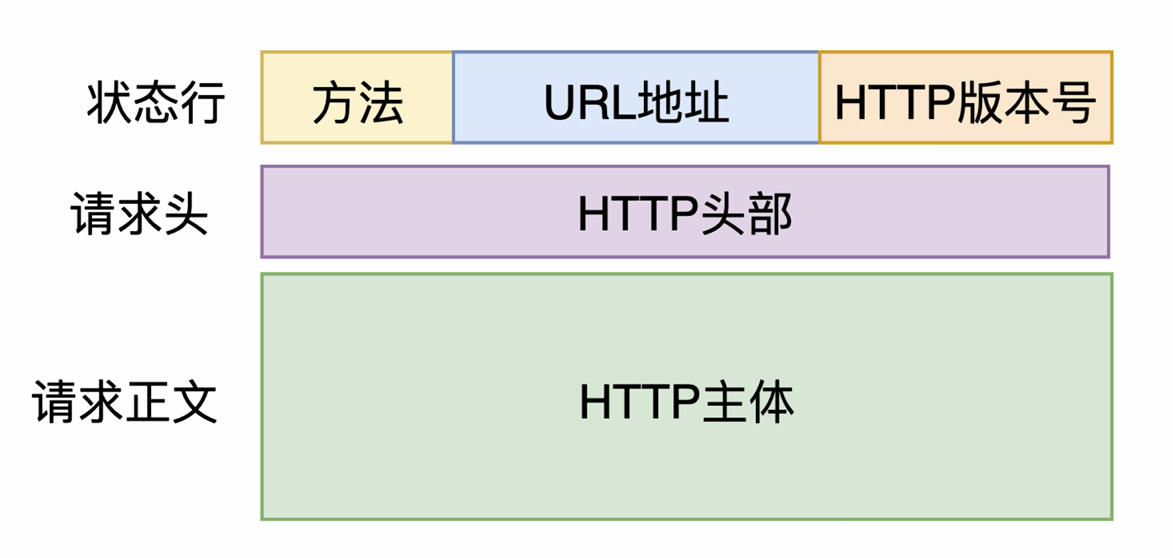
请求报文
请求类型
HTTP 定义了与服务器交互的不同⽅法,最基本的⽅法有4种,分别是GET,POST,PUT,DELETE。URL全称是 资源描述符,⼀个URL地址,它⽤于描述⼀个⽹络上的资源,对应着对资源的查,增,改,删4个操作。

重点关注 GET,POST,PUT,DELETE,HEAD。
get和post区别
GET 可提交的数据量受到URL⻓度的限制,HTTP 协议规范没有对 URL ⻓度进⾏限制。这个限制是特定的浏览器及服务器对它的限制。
理论上讲,POST 是没有⼤⼩限制的,HTTP 协议规范也没有进⾏⼤⼩限制,出于安全考虑,服务器软件在实现时会做⼀定限制。
GET 和 POST 数据内容是⼀模⼀样的,只是位置不同,⼀个在 URL ⾥,⼀个在 HTTP 包的包体⾥。
HTTP 协议中规定 POST 提交的数据必须在 body 部分
post内容类型Content-type
application/x-www-form-urlencoded
最常⻅的 POST 数据提交⽅式。浏览器的原⽣表单,如果不设置 enctype 属性,那么最终就会以这种⽅式提交数据。body 当中的内容和 GET 请求是完全相同的。
multipart/form-data
这⼜是⼀个常⻅的 POST 数据提交的⽅式。我们使⽤表单上传⽂件时,必须让 multipart/form-data 。
application/json
JSON数据类型,用于传输结构化的数据。
text/xml
XML数据类型,用于传输可扩展标记语言(Extensible Markup Language)数据。
application/x-protobuf
用于传输Protocol Buffers(简称Protobuf)数据。⼆进制格式
服务器根据 Content-Type 和 Content-Encoding 解析请求
应答报文
状态行、响应头(Response Header)、 响应正⽂
常见的状态码
- 200 OK 客户端请求成功
- 301 Moved Permanently 请求永久重定向
- 302 Moved Temporarily 请求临时重定向
- 304 Not Modified 文件未修改,可以直接使用缓存的文件。
- 400 Bad Request 由于客户端请求有语法错误,不能被服务器所理解。
- 401 Unauthorized 请求未经授权。这个状态代码必须和WWW-Authenticate报头域⼀起使⽤
- 403 Forbidden 服务器收到请求,但是拒绝提供服务。服务器通常会在响应正⽂中给出不提供服务的原因
- 404 Not Found 请求的资源不存在,例如,输⼊了错误的URL
- 500 Internal Server Error 服务器发⽣不可预期的错误,导致⽆法完成客户端的请求。
- 503 Service Unavailable 服务器当前不能够处理客户端的请求,在⼀段时间之后,服务器可能会恢复正常。
URL
URL全称是资源描述符,⼀个URL地址,它⽤于描述⼀个⽹络上的资源
url字段含义
示例:http://www.testjava.com:9000/ input/test?a=3&b=5….
在URL(Uniform Resource Locator)中,各个字段的含义如下:
- 协议(Protocol):在这个示例中,协议为HTTP(Hypertext Transfer Protocol),它定义了浏览器和服务器之间进行通信的规则。
- 域名(Domain Name):在这个示例中,域名为”www.testjava.com"。它是用于识别和定位网站的字符串,通常由多个部分组成,例如"www"表示主机,"testjava"表示域名的名称,而"com"表示顶级域。
- 端口(Port):在这个示例中,端口号为9000。它用于标识服务器上的特定服务。HTTP协议的默认端口是80,但在这个URL中,使用了非默认的端口号9000。
- 路径(Path):在这个示例中,路径为”/input/test”。它指定了服务器上资源的具体位置或路径。当浏览器发送请求时,服务器将根据路径来定位所需的资源。
- 查询参数(Query Parameters):在这个示例中,查询参数为”a=3&b=5”。查询参数用于向服务器传递额外的信息或数据。它们位于URL路径之后,以问号(?)分隔,多个参数之间使用和号(&)分隔。在这个示例中,参数”a”的值为3,参数”b”的值为5。
url传参
对于数据的传递,HTTP协议提供了两种常见的方式:
数据放在URL中的查询参数:就像上述示例中的查询参数一样,可以将数据直接放在URL中作为查询参数的一部分。这种方式适用于较小的数据,对于敏感数据或需要保密的数据不太安全。
数据放在请求的主体中(Body):对于较大的数据或需要保密的数据,可以将数据放在请求的主体中。这通常用于HTTP的POST请求。数据可以使用不同的格式,例如表单数据(form data)、JSON数据等。在这种情况下,请求头(Headers)中通常会包含一些描述数据的信息,例如Content-Type来指定主体数据的格式。
需要根据实际情况选择将数据放在URL的查询参数中还是请求主体中,通常取决于数据的大小、安全性需求和服务器端的处理方式。
Maven
简介
Maven 是⼀款基于 Java 平台的项⽬管理和整合⼯具,它将项⽬的开发和管理过程抽象成⼀个项⽬对象模型 (POM)。开发⼈员只需要做⼀些简单的配置,Maven 就可以⾃动完成项⽬的编译、测试、打包、发布以及部署 等⼯作。
Maven 是使⽤ Java 语⾔编写的,因此它和 Java ⼀样具有跨平台性,这意味着⽆论是在 Windows ,还是在 Linux 或者 Mac OS 上,都可以使⽤相同的命令进⾏操作。
Maven 使⽤标准的⽬录结构和默认构建⽣命周期,因此开发者⼏乎不⽤花费多少时间就能够⾃动完成项⽬的基础 构建⼯作。
Maven 能够帮助开发者完成以下任务:
构建项⽬
⽣成⽂档
创建报告
维护依赖
软件配置管理
发布
部署
总⽽⾔之,Maven 简化并标准化了项⽬构建过程。它将项⽬的编译,⽣成⽂档,创建报告,发布,部署等任务⽆ 缝衔接,构建成⼀套完整的⽣命周期。
Maven 的⽬标
Maven 的主要⽬标是为为开发⼈员提供如下内容:
⼀个可重复使⽤,可维护且易于理解的项⽬综合模型
与此模型进⾏交互的⼯具和插件
约定优于配置
约定优于配置(Convention Over Configuration)是 Maven 最核⼼的涉及理念之⼀ ,Maven对项⽬的⽬录 结构、测试⽤例命名⽅式等内容都做了规定,凡是使⽤ Maven 管理的项⽬都必须遵守这些规则。 Maven 项⽬构建过程中,会⾃动创建默认项⽬结构,开发⼈员仅需要在相应⽬录结构下放置相应的⽂件即可。
maven的主体框架如下图所示:
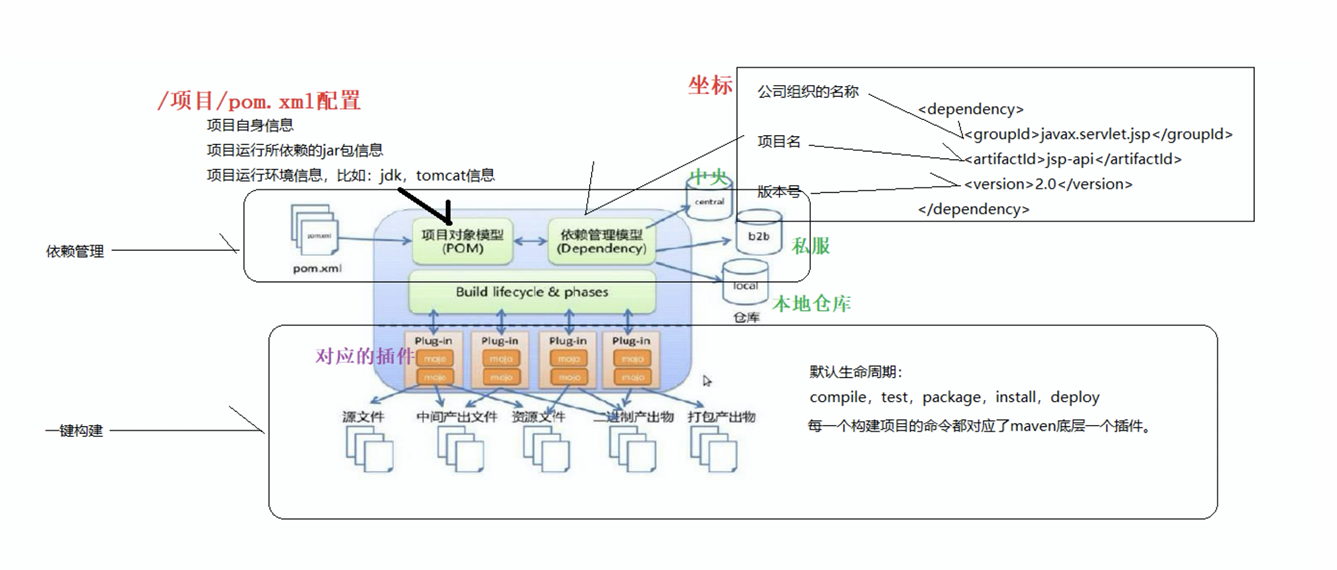
pom.xml文件的作用
Maven项目构建和依赖管理的核心文件。
Maven通过pom.xml文件实现依赖管理,开发者只需要在pom.xml⽂件中给出所需依赖的相应信息,maven会⾃动的从仓库进行依赖下载并完成项目构架。
maven仓库
本地仓库
就是你⾃⼰电脑上的仓库,每个⼈电脑上都有⼀个仓库,默认位置在 当前⽤户名 .m2\repository
私服仓库
⼀般来说是公司内部搭建的 Maven 私服,处于局域⽹中,访问速度较快,这个仓库中存放的 jar ⼀般就是公司内部⾃⼰开发的 jar
中央仓库
有 Apache 团队来维护,包含了⼤部分的 jar,早期不包含 Oracle 数据库驱动,从 2019 年 8 ⽉开 始,包含了 Oracle 驱动
maven常用命令
- mvn clean : 清理,清理target下的目标⽂件
- mvn package : 打包,将源码编译后打包为jar/war,到target下
- mvn compile: 编译源代码
- mvn install: 将软件包安装到本地存储库中,用作本地其他项目的依赖项
- mvn clean package : 清理且打包,⼀起运⾏
- mvn clean package -maven.test.skip=true : 清理且打包,同时跳过test测试
- mvn clean compile package -maven.test.skip=true : 清理编译且打包,同时跳过test测试
- mvn test-compile : 运⾏测试
- mvn depoly: 部署,将生产的目标文件上传到本地仓库和公司仓库
- mvn jetty:run : 调⽤ Jetty 插件的 Run ⽬标在 Jetty Servlet 容器中启动 web 应⽤
二. Servlet 和过滤器
1.Servlet基础
1.Servlet 是什么
Servlet(Server Applet)是Java 程序,具有独立于平台和协议 Servlet的简称,称为小服务程序或服务连接器,用Java编写的服务器端的特性,主要功能在于交互式地浏览和生成数据,生成动态Web内容。
2.servlet的主要功能
- 接收前端⽤户参数
- 动态⽣成返回内容
servlet可以看成是连接用户前端和数据库的桥梁,**==用来处理Web请求,需要部署到tomcat上运行==**。
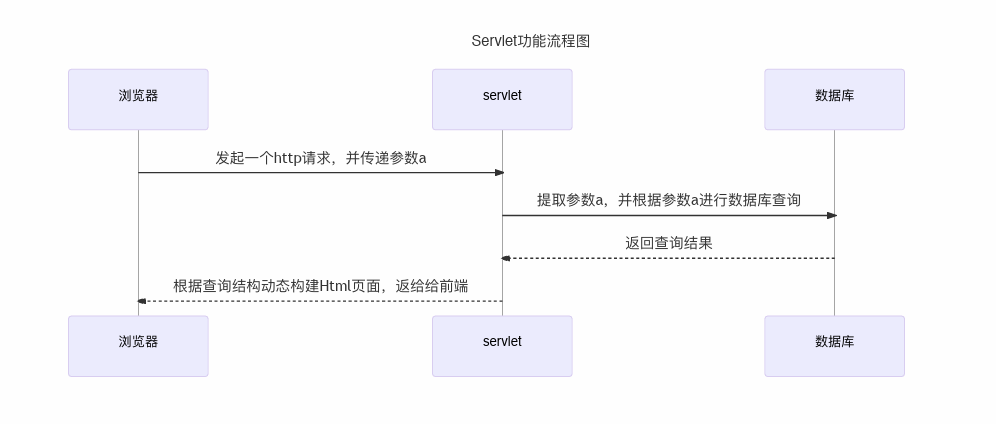
3.部署运行
请注意以下几点:
- Servlet类必须继承HttpServlet基类
- Servlet必须映射到一个url地址,否则无法访问
- Servlet需要实现一个处理http请求方法,如doGet(), doPost()等。
4.代码结构
1 |
|
doGet()方法参数:
- HttpServletRequest 用于封装Http请求报文,获取客户端信息
- HttpServletResponse 用于封装Http响应报文,给客户端返回响应
2.处理Http请求
1.servlet映射到 url 地址
使用@WebServlet("/hello")注解指定映射路径。
拓展:
1 | : |
还可使用web.xml 文件进行映射(仅作了解)
1 | <servlet> |
- 在
web.xml文件中,使用<servlet>元素定义 Servlet,并使用<servlet-name>元素指定 Servlet 的名称。 - 然后,在
<servlet-mapping>元素中,使用<servlet-name>元素指定 Servlet 的名称,并使用<url-pattern>元素指定要映射的 URL 地址模式。 - 在这个示例中,Servlet 类
com.example.MyServlet被映射到 URL 地址模式/myservlet。
2.获取参数-getParameter()
JavaServlet中的HttpServletRequest提供了getParameter()接口用于获取客户端参数。
1 | public String getParameter(String name); |
该方法的参数name为字符串类型,对应于前端的参数名,返回结果为String类型,以字符串形式表示所获取到的参数值。
例如:要获取url http://localhost:8089/handle?age=90&name=Liqiang中的age参数,则代码为
1 | String ageStr = request.getParameter("age"); |
字符串类型转换为其他类型的参考代码如下:
1 | /**其中s为String类型*/ |
注意:当需要获取多选框checkbox值和多个电话号码值的时候,使用了
1 | String[] hobby =request.getParameterValues("hobby"); |
将用户的多个输入值转换为字符串数组。
3.中文乱码问题
中文乱码产生的原因:由于tomcat服务器使用的是西文iso-8859-1的编码方式,而浏览器通常使用中文的GBK或者UTF-8编码进行中文文字的表示,因此在使用Servlet接收中文数据时和输出中文数据时容易产生乱码,解决乱码的方式如下:
解决乱码问题:
(1)接收中文参数:request.setCharacterEncoding("utf-8"); //使用utf-8编码解析字符串
(2)在页面输出中文文字:
1 | //设置输出编码类型和文档类型 |
4.servlet 返回结果
三种方式
返回文本
1
response.getWriter().println("文本");
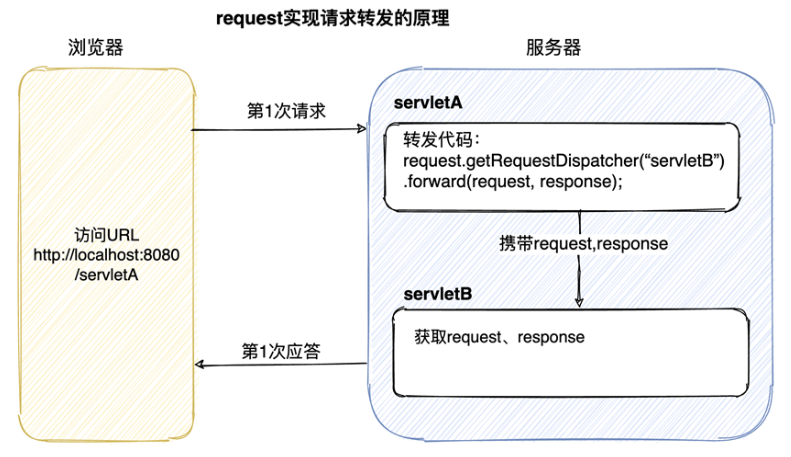
请求转发forward
1
2
3
4String dstUrl = "/index.jsp";//定义跳转的目标url
RequestDispatcher dispatcher = request.getRequestDispatcher(dstUrl);//获取分发器
//实现页面跳转,同时将request,response对象传递到新目标
dispatcher.forward(request, response);也可采用链式调用
1
request.getRequestDispatcher(dstUrl).forward(request, response);
重定向redirect
1
2String dstUrl = "/index.jsp";
response.sendRedirect(dstUrl);
请求转发和重定向跳转方式的区别如下:
- 使用方法:请求转发使用的是分发器forward()方法,分发器由request对象获取;重定向使用的是response对象的sendRedirect();
- 浏览器地址栏:请求转发的浏览器URL地址栏不变;重定向浏览器URL的地址栏改变;
- 实现:请求转发是服务器行为(request),重定向是客户端行为(response);
- 访问次数:转发是浏览器只做了一次访问请求;重定向是浏览器做了至少两次的访问请求;
- 数据传递:请求转发允许将对象数据传递到下一个目标资源,而重定新不可以;
- 资源范围:请求转发只能跳转到服务器内部资源;重定向可以调整到服务器外部
工作流程
请求转发forward
- 客户端发送Http请求数据给服务器
- 服务器接收请求数据并调用第一个Servlet处理逻辑
- 第一个Servlet处理完数据后调用forward()方法将请求传递给服务器内部的下一个Servlet
- 第二个servlet处理完数据后将最终处理结果返回给客户端
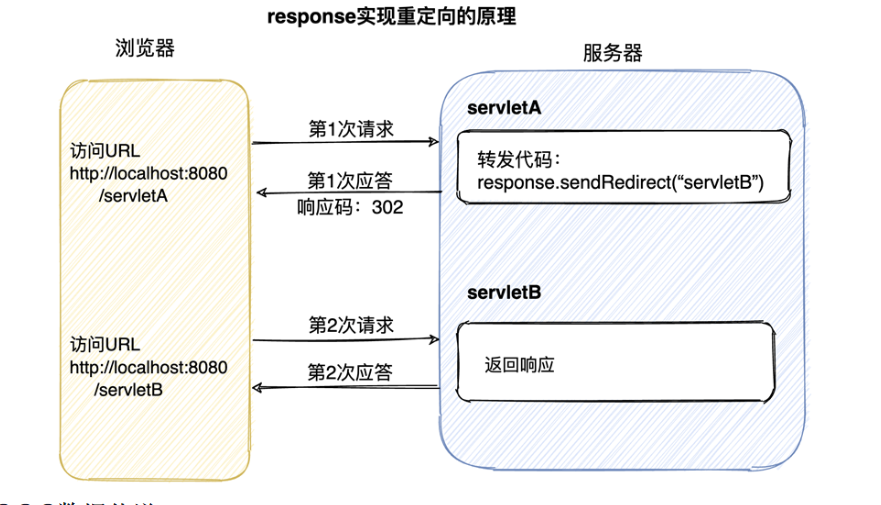
重定向redirect
- 客户端发送Http请求数据给服务器
- 服务器接收请求数据并调用一个Servlet处理逻辑
- 服务器调用sendRedirect()方法将处理结果放进HTTP响应头中并返回给客户端
- 客户端收到响应结果后,从HTTP响应头中取得相关信息,再次发送请求数据给服务器。
示例
1 | /** |
5.servlet处理 HTTP 不同类型请求
- Servlet的service()方法是请求的入口方法,HttpServlet实现service()方法在这个入口方法中根据不同的Http请求方法(如GET、POST请求)调用不同的方法。
- HttpServlet中的Service方法会检验用来发送请求的HTTP方法(通过调用request.getMethod() ),并调用以下方法之一:
doGet、doPost、doHead、doPut、doTrace、doOptions、doDelete.
对应生命周期的服务周期。
3.Servlet 的生命周期
1.四个周期
Servlet的生命分为以下4部分:Servlet实例化–>初始化–>服务–>销毁
(1)实例化。对应于new方法。当Servlet第一次被访问时,Web容器将会加载相应的Servlet到Java虚拟机并执行实例化,此时会生成一个Servlet对象。
(2)初始化,对应于init方法。当Servlet容器创建后,会调用并且仅调用一次init()方法,用于初始化Servlet对象。无论有多少客户机访问Servlet,都不会重复执行init()。
(3)服务。对应service方法。service()方法是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应”(ServletResponse)对象作为参数。实际执行中是根据Http请求方法调用相应的do功能。
(4)销毁,对应destroy方法。destroy()方法仅执行一次,只在Web服务器端停止并卸载Servlet时执行。当Servlet对象被销毁时,将释放其占用的资源。
Servlet接口类中提供了Servlet生命周期中3个方法的定义,相关功能说明如下:
1 | public interface Servlet { |
在HttpServlet类中提供了service方法的具体实现,service()方法主要根据Http请求方法的不同调用不同的do方法进行处理。
注意几点:
(1)一个Servlet对象只有在第一次访问时被创建,之后将常驻内存,并使用该对象处理后的用户请求;inti()方法
(2)一个Servlet对象在处理不同的客户端请求时,往往使用多线程执行,即针对每一个客户端请求开启一个线程;
(3)Servlet只有在web容器重启或者停止时候才会被销毁。destroy()方法
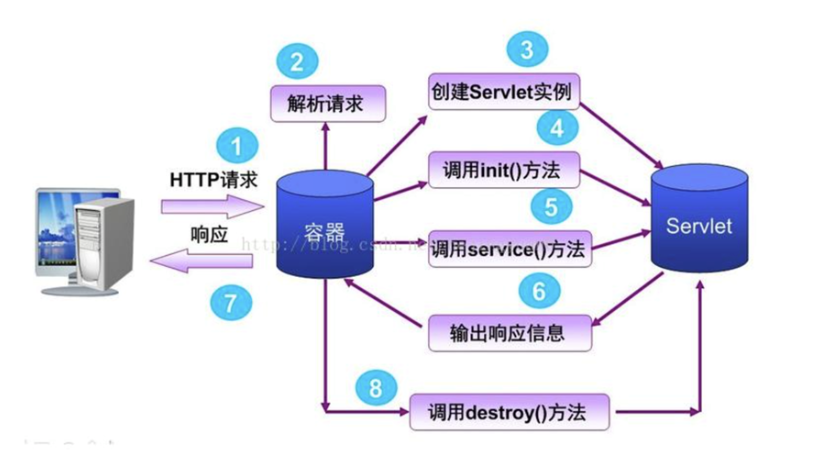
2.Servlet处理请求的过程
(1)客户端发送请求给服务器。
(2)容器根据请求及web.xml判断对应的Servlet是否存在,如果不存在则返回404。
(3)容器根据请求及web.xml判断对应的Servlet是否已经被实例化,若是相应的Servlet没有被实例化,则容器将会加载相应的Servlet到Java虚拟机并实例化。
(4)调用实例对象的service()方法,并开启一个新的线程去执行相关处理。调用servce方法,判断是调用doGet方法还是doPost方法。
(5)业务完成后响应相关的页面发送给客户端。
4.过滤器FIlter
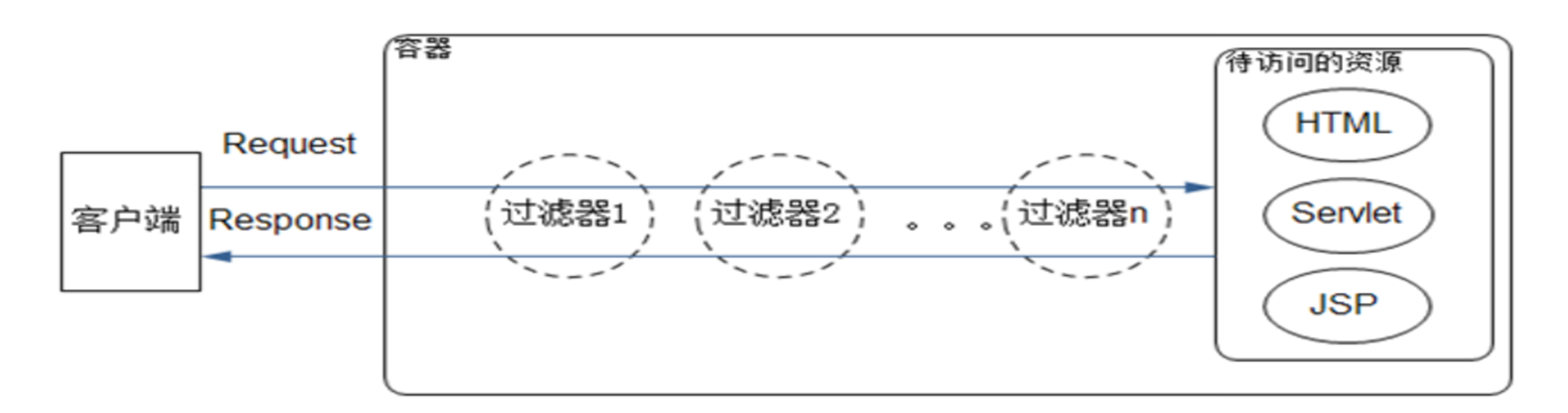
1.过滤器用途和工作原理
用途:
过滤器是一种Web组件,用于对客户端发送的请求信息和服务器返回的响应结果进行处理。即可以拦截请求和应答
工作原理:
- 通过使用过滤器,可以拦截客户端的请求和响应,查看、提取或者以某种方式操作正在客户端和服务器之间进行交换的数据。
- 通过使用过滤器,可以对Web组件的前期处理和后期处理进行控制。
- 过滤器可以有多个,以构成一个过滤器链。Servlet容器会根据过滤器的配置情况来决定过滤器的调用次序。
过滤器使用的设计模式为责任链设计模式
2.应用场景
- EncodingFilter 字符编码过滤器 点击查看示例
用于设置 HTTP 请求字符编码的过滤器,通过过滤器参数encoding指明使用何种字符编码,用于处理Html Form请求参数的中文问题。 - AuthorityFilter 权限过滤器点击查看示例
在一个系统中通常有多个权限的用户。不同权限用户的可以浏览不同的页面。使用Filter进行判断不仅省下了代码量,而且如果要更改的话只需要在Filter文件里动下就可以。
3.过滤器的部署
1.定义的过滤器类必须要实现接口javax.servlet.Filter,并且实现该接口中定义的3个方法:
- vod init(…):用于初始化过滤器。
- void destroy():用于销毁过滤器。
- void doFilter(…):用于执行过滤操作。
2.在web.xml配置文件中部署Filter
用
用来设定过滤器的名字 用来设定过滤器的类路径
用
用来设定过滤器的名字 用来设定被过滤的组件
3.用@WebFilter(“/*”)部署
若用注解部署过滤器链则会随机调用过滤器,即无顺序
示例:
编码过滤器
1 | public class EncodingFilter implements Filter { |
1 | <filter> |
用户权限过滤器
1 | public class AuthenFilter implements Filter { |
1 | <filter> |
4.过滤器链
过滤器链的顺序是根据web.xml配置文件中
三. Spring IOC 和单例设计模式
1.Spring 的核心IOC 和 AOP
IoC(Inverse of Control 控制反转)
控制反转:对象的创建交给外部容器完成。不直接在代码中创建对象。
IOC 容器的作用
- 依赖处理,通过依赖查找或者依赖注入
- 管理托管的资源(Java Bean 或其他资源)的生命周期
- 管理配置(容器配置、外部化配置、托管的资源的配置)
控制反转解决对象的管理(创建、销毁等)问题。
依赖注入(dependency injection):实现对象之间的依赖关系。在创建完对象之后,对象之间的关系处理就是依赖注入。
Spring提供了IOC容器。无论创建对象、处理对象之间的依赖关系、对象创建的时间还是数量,都在Spring IOC容器配置完成。
IOC核心思想:资源不由资源的使用方管理,而由不使用资源的第三方管理。
好处(为什么要控制反转):
(1)资源集中管理,实现资源的可配置和易管理;
(2)降低使用资源双方的依赖程度。
AOP(Aspect Oriented Programming 面向切面编程)
通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。AOP是OOP的延续,是软件开发中的一个 热点,也是Spring框架中的一个重要内容,是函数式编程的一种衍生范型。利用AOP可以对业务逻辑 的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
2.IOC 容器中对象的注入和装配
spring 默认采用单例模式对管理 Bean 对象
基于 xml
基于 XML 的 Bean 装配是最基本的 Bean 装配方式之一。 在基于 XML 的 Spring 配置中声明一个 bean,使用 spring-beans 模式元素,参考如下:<bean id=".." class="…" />
Bean实体类
1 |
|
spring-config.xml文件
1 |
|
1 | public static void main(String[] args){ |
基于注解
基于注解的自动化 Bean 装配是最常用 Bean 装配方式之一。需要我们对 Spring 的常用注解有个基本认识。spring 注解可以减少 xml 配置;利用 Java 的反射机制获取类结构信息,有效减少配置的工作。
1 | public interface CompactDisc { |
1 | //Spring 会自动扫描,生成该 Java 类对应的 Bean 实例。 |
1 |
|
spring-config.xml 文件配置,指定类所在包
1 | <context:component-scan base-package="com.javaee"/> |
测试
1 | public class TestJavaCfg { |
结果如下:
1 | 演示Spring的自动扫描装配 |
注解总结
@Component:代表 Spring IoC 会把该java类扫描生成 Bean 实例,位于 Java 类声明之前。对象 id 为类名第一个字母小写,即 CdPlayer 对应的 Bean id 为 cdPlayer。
@Autowired:实现属性自动装配,Spring 会根据类型去寻找定义的 Bean 然后进行byType注入,如果需要 byName(byName 就是通 过 id 去标识)注入,增加@Qualifier 注释。例如上文中需要注入的是NovChopinCD类:
1 |
|
基于 Java 配置类
通过 java 配置类配置 Bean 的优点:
(1)更加强大:自动装配实现的功能,它都能实现,还能实现自动装配不能实现的功能。
(2)容易理解:通过 java 代码原生态的方式来配置 Bean,代 码读起来也比较容易理解。
(3)类型安全并且对重构友好
1 | public class MyBean { |
1 |
|
1 | public class BeanTest { |
结果如下:
1 | This is MyBean |
注解总结
@Configuration:表示该类是一个配置类并用于构建 bean 定义,初始化 Spring 容器,被注解类包含有一个或多个被@Bean 注解的方法,这些方法将会被 AnnotationConfigApplicationContext 或 AnnotationConfigWebApplicationContext 类进行扫描
@ComponentScan:扫描定义的包,如@ComponentScan( basePackages = “jee.java.config” )
@Bean:表明该类交由Spring管理,若未指定名称,默认采用的是“方法名”+“首字母小写”的配置方式,即方法mybean的id为mybean。
3.单例设计模式
定义:
只需要三步就可以保证对象的唯一性
(1) 不允许其他程序用new对象,即私有化该类的构造函数
(2) 在该类中创建对象
(3) 对外提供一个可以让其他程序获取该对象的方法
优点
单例模式主要是为了避免因为创建了多个实例造成资源的浪费,且多个实例由于多次调用容易导致结果结果出现错误,而使用单例模式能够保证整个应用中有且只有一个实例。
懒汉式,没有考虑线程安全,比饿汉更节省资源。
1 | public class Singleton { |
饿汉式,没有懒加载,可能会造成内存的浪费
实现比较简单,在类加载的时候就完成了实例化,避免了线程的同步问题。
1 | public class Singleton{ |
四. SpringBoot 核心配置
1.SpringBoot 框架的特点
•可快速构建独立的Spring应用
•直接嵌入Tomcat、Jetty和Undertow服务器(无需部署WAR文件)
•提供依赖启动器简化构建配置
•极大程度的自动化配置Spring和第三方库
•提供生产就绪功能
•极少的代码生成和XML配置
•约定大于配置
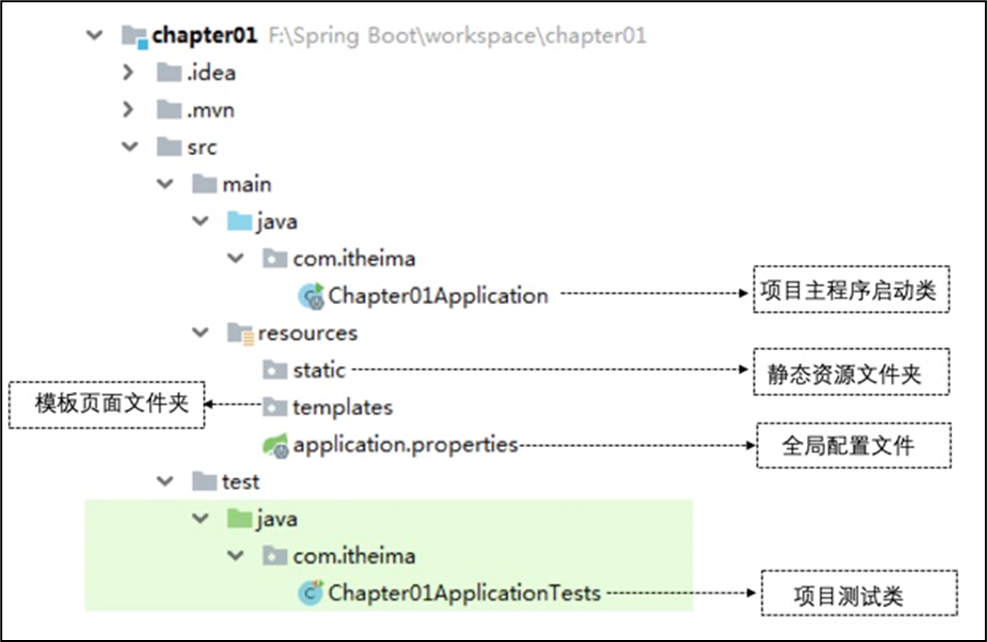
2.springboot 项目的代码结构
3.SpringBoot 的配置文件
application.properties
1 | server.address=80 |
application.yaml
•YAML文件格式是Spring Boot支持的一种JSON超集文件格式。
•相较于传统的Properties配置文件,YAML文件以数据为核心,是一种更为直观且容易被电脑识别的数据序列化格式。
•application.yaml文件的工作原理和application.properties一样。
语法格式:key:(空格)value 缩进 2 个空格
- value的值为普通数据类型
1 | server: |
- value的值为数组和单列集合
1 | //缩进式写法 |
- value的值为Map集合或对象
1 | //缩进式写法 |
4.配置文件的属性值的注入
@ConfigurationProperties(注入到整个类)
使用@ConfigurationProperties注解批量注入属性值时,要保证配置文件中的属性与对应实体类的属性一致,否则无法正确获取并注入属性值。
@ConfigurationProperties其实可以看成多个@Value注入
1 |
|
application.yaml
1 | person: |
@Value()单个值的注入
语法:@Value(“${key}”)
1 |
|
两种注解的对比分析
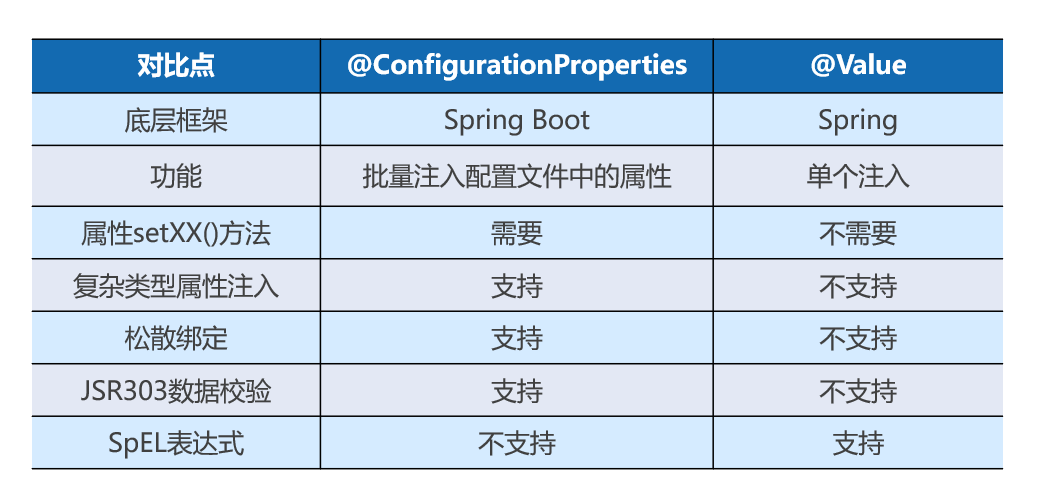
关键:@ConfigurationProperties需要有set(),@Value无需set方法。
五. SpringBoot Web 层
1.映射到 URL
@RequestMapping是SpringBoot提供的⼀个地址映射的基础注解,主要⽤途是将Web请求与请求处理类中的⽅法 进⾏映射。
@RequestMapping注解拥有以下的六个配置属性:
- value :映射的请求URL或者其别名
- method :兼容HTTP的⽅法名
- params :根据HTTP参数的存在、缺省或值对请求进⾏过滤
- header :根据HTTP Header的存在、缺省或值对请求进⾏过滤
- consume :设定在HTTP请求正⽂中允许使⽤的媒体类型
- product :在HTTP响应体中允许使⽤的媒体类型
1 |
|
也可以采⽤分层的形式表示
1 |
映射到多个URL地址
1 |
|
在Spring5之后,出现了更简单的Http 请求⽅法映射的注解,分别是:
@GetMapping ⽤于处理HTTP GET请求
@PostMapping ⽤于处理HTTP POST请求
@PutMapping ⽤于处理HTTP PUT请求
@DeleteMapping ⽤于处理HTTP DELETE请求
@PatchMapping ⽤于处理HTTP PATCH请求
1 |
|
注意在类前还需@RequestMapping(“api”)。
2.返回结果
返回结果类型通常包括:返回HTML页面,返回JSON文本数据。
在控制器类上标注@Controller 注解,则方法默认返回页面视图,即HTML页面。
在方法上如果使用@ResponseBody 注解,则直接将返回值序列化json。
使用Model可以将数据传递到视图页面,下面两种写法功能相同。ModelAndView同时包含了视图和模型对象。

在控制器类上标注@RestController,则所有方法都返回JSON数据。可以在方法返回Map对象,该
对象会自动被转换为JSON数据格式。
3.控制器和Servlet的区别
•1.一个Servlet类只能处理一个HTTP请求,需要通过action等参数进行类别区分;
•2. Servlet获取前端数据比较低级,需要手动进行转换;
•3.后端数据校验需要手动完成;
•4.使用response输出响应比较繁琐;
•5.页面跳转代码复杂;
4.@Controller和@RestController的区别
@RestController = @Controller + @ResonseBody
使用**@Controller注解作用于类声明时,当方法返回值为String类型,默认表示返回该字符串对应的页面视图**,该页面后缀为.html,位于resourses/templates目录下。在方法前面使用@ResponseBody表示返回文本数据。
使用**@RestController注解作用于类声明时,表示该类所有的方法均返回文本数据**,而非返回视图页面名称。
@Controller返回页面视图名称时,需要添加Thymeleaf依赖放起到效果。
5.前端参数的获取
获取单个参数--@RequestParam
/test/hello?a=123 key=value 类型
1 |
|
上述过程没有显式指定@RequestParam的value或name属性,因此形参名必须与请求参数名⼀⼀对应。如果我 们显式指定了value或name属性,那么形参名就可以任意了:
1 |
|
- @RequestParam标注在⽅法形参上,⽤来获取HTTP请求参数值。
- 如果形参为基本类型,可以获取对应的请求参数值。此时需要注意请求参数名是否需要与形参名⼀致(是否 指定value或name属性)。
- 如果形参为Map或MultiValueMap,则可以⼀次性获取全部请求参 数。此时请求参数名与形参名⽆关。
- required属性默认为true,此时必须保证HTTP请求中包含与形参⼀致的请求参数,否则会报错。
- 我们可以使⽤defaultValue属性指定默认值,此时required⾃动指定成false,表示如果没有提供该请 求参数,则会使⽤该值。
例如:
1 |
|
获取路径参数--@PathVariable
路径变量/test/hello/123
1 |
|
获取JSON格式的参数值--@RequestBody
@RequestBody标注在⽅法形参上,⽤来接收HTTP请求体中的json数据。
注意:由于Json数据只能通过POST请求进⾏传递(数据存放在Http Body中),因此@RequestBody需要 和@PostMapping配置使⽤,此时不能使⽤GET请求。此时Content-Type对应的值为 application/json。
Spring会使⽤HttpMessageConverter对象⾃动将对应的数据解析成指定的Java对象。例如,我们发送如下 HTTP请求:
1 | POST http://localhost:8080/student |
1 |
|
⼀般来说在Controller⽅法中仅可声明⼀个@RequestBody注解的参数,将请求体中的所有数据转换成对应的 POJO对象。
6.发送响应数据
@ResponseBody
@ResponseBody可以标注在类或⽅法上,它的作⽤是将⽅法返回值作为HTTP响应体发回给客户端, 与@ResquestBody刚好相反。 我们可以将它标注到⽅法上,表示仅有handle()⽅法的返回值会被直接绑定到响应体中,注意到此时类标注成@Controller:
1 |
|
我们也可以将它标注到类上,表示类中所有⽅法的返回值都会被直接绑定到响应体中:
1 |
|
此时,@ResponseBody和@Controller相结合,就变成了@RestController注解,也是前后端分离中最常⽤的 注解:
1 |
|
如果客户端发送如下HTTP请求:GET http://localhost:8080/student。此时上述代码都会有相同的HTTP响 应,表示接收到student的json数据:
1 | 200 |
总结@ResponseBody的⽤法:
- @ResponseBody表示将⽅法返回值直接绑定到web响应体中。
- @ResponseBody可以标注到类或⽅法上。类上表示内部所有⽅法的返回值都直接绑定到响应体中,⽅法上表 示仅有该⽅法的返回值直接绑定到响应体中。
- @ResponseBody标注到类上时,与@Controller相结合可以简写成@RestController,这也是通常使⽤的注解。 我们可以灵活地构造合适的返回对象,结合@ResponseBody,⽤作与实际项⽬最匹配的响应体返回。
7.数据校验
@Valid-POJO类校验
实现方法:
(1)在POJO类的属性添加对应的校验注解。
(2)在控制器方法中使用@Valid注解表示对参数进行校验,同时后面使用Errors/BindingResult来捕获错误信息,并进行处理。
1 |
|
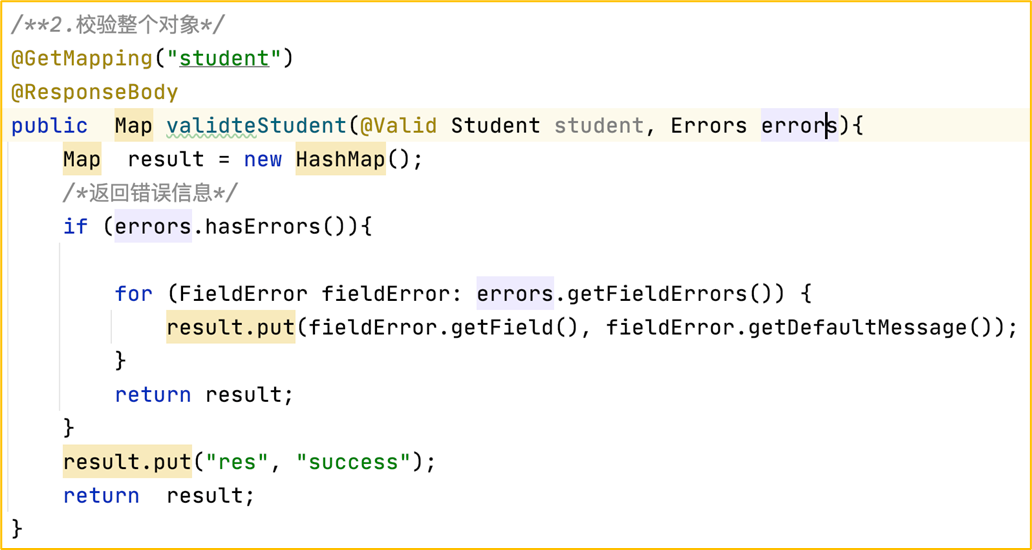
@Validated-方法参数合法性校验
实现方法:
- 在控制器类标注@Validated 注解。
- 在方法中可以使用JSR303提供的注解来完成校验,例如@NotNull等。
1 |
|
@Valid和@Validated的区别
@Valid是使用Hibernate validation的时候使用
@Validated是只用Spring Validator校验机制使用
说明:java的JSR303声明了@Valid这类接口,而Hibernate-validator对其进行了实现。
注解位置:
@Validated:用在类型、方法和方法参数上。但不能用于成员属性(field)
@Valid:可以用在方法、构造函数、方法参数和成员属性(field)上
六. Mybatis – ORM
持久化是程序数据在瞬时状态和持久状态间转换的过程
1.ORM(Object Relational Mapping)
编写程序的时候,以面向对象的方式处理数据
保存数据的时候,却以关系型数据库的方式存储
ORM就是一种为了解决面向对象与关系型数据库中数据类型不匹配的技术,它通过描述Java对象与数据库表之间的映射关系,自动将Java应用程序中的对象持久化到关系型数据库的表中。
ORM解决方案包含下面四个部分
- 在持久化对象上执行基本的增、删、改、查操作
- 对持久化对象提供一种查询语言或者API
- 对象关系映射工具
- 提供与事务对象交互、执行检查、延迟加载以及其他优化功能
2.Mybatis和ORM
MyBatis是一个数据持久层(ORM)框架。把实体类和SQL语句之间建立了映射关系,是一种半自动化的ORM实现
MyBatis的工作原理
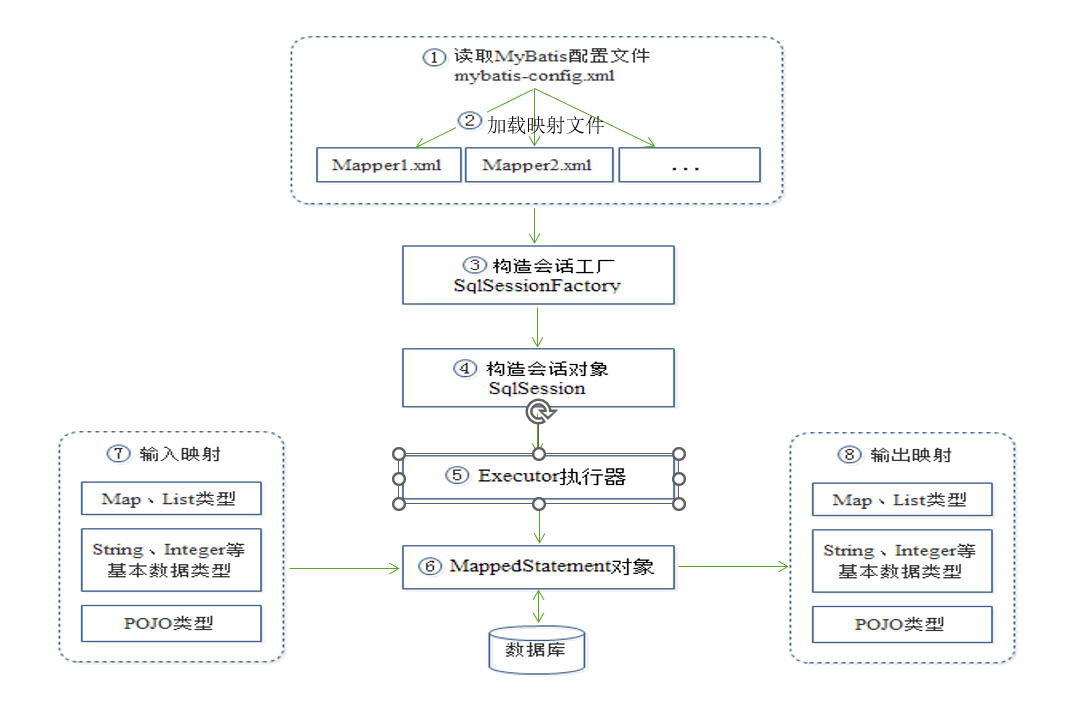
3.MySQL数据查询分页查询SQL
1 | select * from 表名 limit start,count |
limit
说明:
- limit是分页查询关键字
- start表示开始行索引,默认是0
- count表示查询条数
limit0,10 表示从0开始查询十条数据
n:求第几页的数据
m:每页显示m条数据
1 | 公式: |
分页查询前端需要传递两个参数
1、pageNo,因为点第几页是用户决定的。所以需要传参数。
2、pageSize,因为用户可选每页展示条数(如10,20,50等)(其实如果固定分页大小的话,这个参数可以不传)
对应limit start,count
4.Mapper 层代码的编写@Mapper
1 |
|
接收参数
1 | Select * from user as u where u.name=#{username} |
5.Mybatis 整合的两种方式
基于注解
1 | /** 根据id查询对象 */ |
为了获取新记录的主键,需要将属性useGeneratedKeys设置为 true,同时设置keyColumn(对应数据表主键字段)和 keyProperty(对象的主键属性)。新增主键值将回填到teacher对象中
基于XML映射文件
在映射文件中,
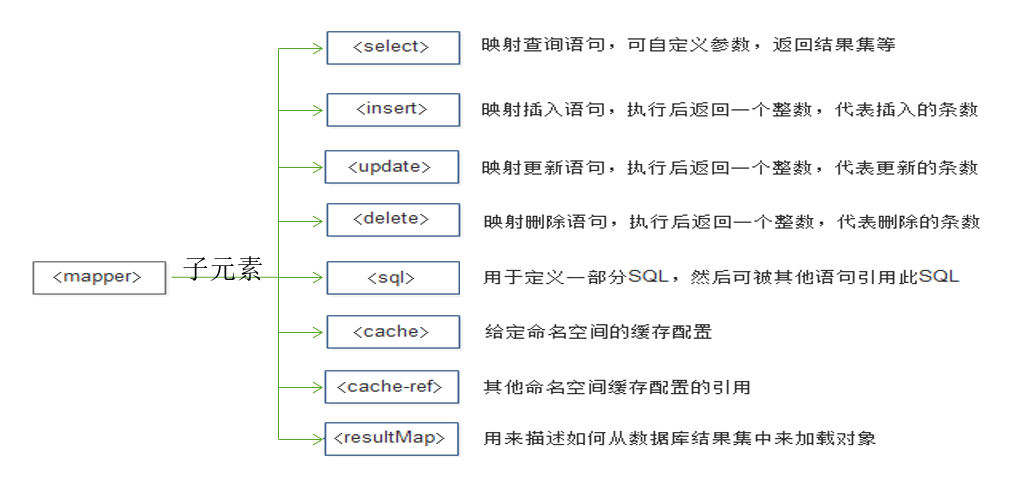
xml映射文件通常放在resouces目录下的mapper文件夹中。内容构造如下:
1 |
|
1 | <select id="getById" resultType="Student"> |
6.Mybatis 接口的传参
1. 单个参数传递
1 | //在接口中定义放法,参数形式如下 |
1 | <!-- |
1 | //调用方法时只需要传入相应类型的单个值即可 |
2. 使用@param为参数命名传递多个参数
1 | /* 在接口文件的对应方法形参中,使用以下格式进行命名 |
1 | //调用时传入对应的参数值 |
1 | <!-- |
3. 使用Java对象作为方法的参数
1 | //在接口中定义方法,参数形式如下 |
1 | <!-- |
1 | //调用时传入相应对象 |
4. 使用位置传参
在方法的参数中,形参的顺序对应映射文件中参数的顺序,arg0指形参中第一个值,arg1代表第二个,以此类推。
1 | //在接口中定义放法,参数形式如下 |
1 | <!--根据参数位置传参 arg后面的数字代表参数所在的位置--> |
1 | //调用代码 |
5. 使用map传参
1 | //在接口中定义放法,参数形式如下 |
1 | <!--使用Map键值对传参,形式:#{key名}--> |
1 | //调用 |
7.基于mybatis的模糊查询
1 | <select id="fuzzyQuery" resultType="com.bin.pojo.Book"> |
like concat关键字
1 | <select id="fuzzyQuery" resultType="com.bin.pojo.Book"> |
8.基于Mybatis的动态多条件查询
if
1 | <select id="findByNameAndClassNo" |
where 1=1⽤于保证SQL语法正确性。如果没有添加1=1,则当name和home_address都为空时, SQL语句将变为 select * from student where,成为⼀个⾮法的SQL语句。
where
使⽤“where”标签会根据它包含的标签中是否有返回值,进⾏‘where’关键词的插⼊。另外,如果标签返回的内容 是以AND 或OR 开头的,则会删除。使⽤where标签之后将不在需要之前的1=1的条件,上述联合查询功能使⽤ where标签实现的具体代码如下:
1 | <select id="findByNameAndClassNo" |
set
Set标签⽤于动态更新语句。set 元素可以⽤于动态包含需要更新的列,忽略其它不更新的列。例如,程序只需要更 新student⾮空的属性值,mapper接⼝类代码为:
1 | public int updateIfExists(Student student); |
1 | <update id="updateIfExists"> |
foreach
批量操作是数据操作常常碰到的情景,例如要导⼊⼀个excel⽂件记录到数据中,往往需要使⽤批量插⼊的⽅式来 提⾼效率,同时,批量删除和其他的批量处理也是业务中经常碰到的操作。此时,可以foreach标签来实现批量操 作。foreach可以遍历指定集合,动态构造所需的 SQL语句。。⽐如:
1 | <select id="selectPostIn" resultType="domain.blog.Post"> |
foreach 元素的功能⾮常强⼤,它允许你指定⼀个集合,声明可以在元素体内使⽤的集合项(item)和索引 (index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加 多余的分隔符,看它多智能!
提示 : 你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使 ⽤可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使⽤ Map 对象(或 者 Map.Entry 对象的集合)时,index 是键,item 是值。
批量插⼊数据:
1 | /**批量插⼊*/ |
1 | <!-- 批量插⼊--> |
注意:和insert插⼊操作⼀样,需要使⽤useGeneratedKeys属性值才能获得主键id并回填到对象
批量删除
1 | /**批量删除*/ |
1 | <!--批量删除--> |
SQL⽚段 sql
有时候可能某个 sql 语句我们⽤的特别多,为了增加代码的重⽤性,简化代码,我们需要将这些代码抽取出来,然 后使⽤时直接调⽤。代码⽚段的使⽤分为代码⽚段定义和使⽤两部分。
定义⽚段
1 | <sql id="selectall"> |
使⽤⽚段
1 | <select id="selectStudent" resultType="Student"> |
script
要在带注解的映射器接⼝类中使⽤动态 SQL,可以使⽤ script 元素。⽐如
1 |
|
9.Mybatis-plus
MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
10.对象关联关系
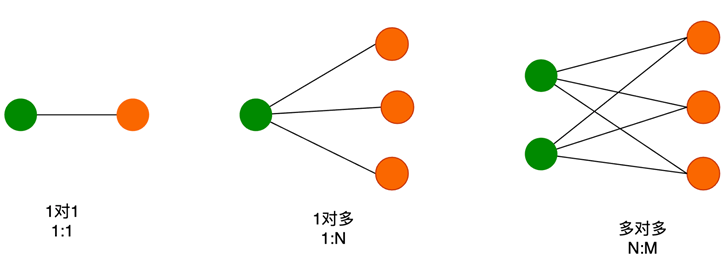
一对一
- 主键共享
两张表的主键,建立外键约束。 - 外键唯一
子表添加一个新的字段并给该字段添加唯一约束和外键约束,然后关联父表主键字段。
一对多
- 外键添加在多的一方,关联一的主键。
多对多
- 中间表:创建一个中间表,中间表的两个普通字段分别关联另两张表的主键。
七. Redis 缓存和RabbitMQ
1.Redis
Redis 完全是基于内存的操作,所以很快。还有因为key-value结构简单。是一个高性能的key-value非关系型数据库
端口号6379
redis的实现原理
- 内存存储:Redis 将数据存储在主内存中,以实现高速的读写操作。它使用自己的内存分配器,对内存进行高效管理,并通过哈希表等数据结构提供快速的数据访问。
- 单线程模型:Redis 采用单线程模型来处理客户端的请求。这是因为 Redis 的瓶颈通常在于 CPU 的处理能力,而不是线程的并发性。单线程模型简化了数据结构的实现和锁的管理,并减少了线程切换的开销。
- 基于事件驱动的异步 I/O:Redis 使用事件驱动的网络模型来处理客户端请求和网络通信。它使用 epoll 或 kqueue 等操作系统提供的机制监听网络事件,一旦有事件发生,就会触发相应的回调函数进行处理。这种异步的 I/O 模型使得 Redis 能够支持高并发的网络连接。
- 持久化机制:Redis 提供了两种持久化机制,即快照(snapshotting)和日志(append-only file)。快照通过将数据集的副本写入磁盘,以恢复数据集的状态。日志记录了写操作的命令,通过回放日志来还原数据集。这两种机制可以单独或同时使用,以满足不同的需求。
- 命令的原子性:Redis 的命令是原子性的,即每个命令要么完全执行,要么完全不执行。它使用事务和乐观锁机制来保证多个命令的原子性操作。事务通过将一组命令打包在一个单独的步骤中执行,而乐观锁则在执行命令之前检查数据是否被其他客户端修改。
- 高可用性和复制:Redis 支持主从复制机制,可以将一个 Redis 服务器配置为主服务器,而其他服务器作为从服务器进行复制。主服务器负责处理写操作,从服务器负责复制主服务器的数据并处理读操作。这样可以提高系统的可用性和容错性。
redis整合Springboot主要注解
@EnableCache 开启基于注解的缓存功能
@Cacheable注解 :先从redis数据库中 按照当前key查找,有没有。如果redis中有,是不会走当前该方法的,如果没有再调用方法返回结果,如果结果不为null将其缓存到数据库中(一般用于find)
1 |
|
@CachePut: 主要用于向数据库中插入数据,向数据中插入数据的时候,会将返回的int类型,放入redis中缓存,当然是有选择性的(一般用于insert)
1 |
|
@CacheEvict:满足条件则移除当前key在redis中的数据(一般用于update/delete)
1 |
|
Redis实现和数据库的数据一致性
- 读写分离:通过将数据库的读操作和写操作分别路由到不同的实例或节点,可以实现读写分离。写操作可以直接写入数据库,而读操作则可以从Redis中获取数据,从而实现数据库与Redis之间的数据一致性。
- 延迟双写:在写入数据库之前,先将数据写入Redis。然后,通过异步方式将数据写入数据库,可以减少写入数据库的频率,提高系统的性能。虽然在写入数据库之前存在一定的延迟,但通过合理的设计和配置,可以确保数据的最终一致性。
- 事务和队列:Redis支持事务(Transaction)和消息队列(Message Queue),可以将数据库的写操作和Redis的写操作放入同一个事务中或者将写操作作为消息放入队列中。通过事务或队列的机制,可以确保数据库和Redis中的写操作要么同时成功,要么同时失败,从而实现数据的一致性。
- 缓存更新策略:当数据库中的数据发生变化时,需要及时更新Redis中的缓存数据。可以采用主动更新(Active Updating)或被动更新(Passive Updating)策略。主动更新是在数据库数据变化时主动触发更新Redis缓存,而被动更新是在Redis缓存被访问时检查数据是否过期,过期则重新从数据库加载。这些策略可以根据具体场景和需求进行选择和调整。
- 数据同步和复制:如果需要在多个Redis节点之间实现数据一致性,可以使用Redis的复制机制。通过将一个Redis节点配置为主节点,而其他节点配置为从节点,主节点负责处理写操作并将数据复制到从节点。这样可以确保主节点和从节点之间的数据一致性。
2.rabbitMQ
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue 高级消息队列协议 )的开源实现,能够实现异步消息处理
rabbitMQ是一个消息代理:它接受和转发消息。
应用场景
- 异步处理
- 应用解耦
- 流量削峰
- 分布式事务管理
网页客户端端口号:15672
配置端口号:5672
rabbitMQ的几个概念
- 交换器(Exchanges):交换器是消息的发布者发送消息的地方。它接收来自生产者的消息并将其路由到一个或多个队列。交换器根据定义的规则(路由键)决定消息将被发送到哪个队列。
fanout类型的交换器会将消息广播到所有绑定到该交换器的队列中。它不关心消息的路由键(routing key),只是简单地将消息发送到所有绑定的队列。header类型的交换器使用消息的header信息进行匹配,根据header的键值对来确定消息路由到哪些队列。topic类型的交换器使用模式匹配的方式将消息路由到队列。消息的路由键(routing key)和交换器的绑定键(binding key)之间使用通配符进行匹配。direct类型的交换器根据消息的路由键(routing key)和交换器的绑定键(binding key)进行精确匹配,将消息路由到指定的队列。
- 队列(Queues):队列是RabbitMQ中的消息容器,它存储等待被消费者处理的消息。当消息被发送到队列时,它们会被保存在队列中直到被消费者接收。消费者可以按照顺序接收队列中的消息。
- 消息确认(Message Acknowledgment):消息确认是一种机制,用于确认消息已被消费者接收和处理。当消息被消费者处理后,它可以发送一个确认给RabbitMQ,告知它可以删除该消息。
rabbitMQ的工作模式
- 简单模式(Simple Mode):在简单模式下,一个生产者向一个队列发送消息,一个消费者从该队列接收并处理消息。这是最基本的模式,适用于单个生产者和单个消费者的情况。
- 工作队列模式(Work Queue Mode):在工作队列模式下,一个生产者向一个队列发送消息,多个消费者从同一个队列接收消息并进行处理。消息会被平均分配给不同的消费者,以实现负载均衡。适用于并行处理任务的场景。
- 发布-订阅模式(Publish-Subscribe Mode):在发布-订阅模式下,一个生产者发送消息到一个交换器,交换器将消息广播给绑定到它的所有队列。每个队列都有自己的消费者,它们独立地接收并处理消息。适用于需要将消息广播给多个消费者的场景。
- 路由模式(Routing Mode):在路由模式下,生产者发送带有路由键的消息到交换器,交换器根据路由键将消息发送到与之匹配的队列。每个队列都有自己的消费者,它们只接收与队列绑定的特定路由键匹配的消息。适用于根据不同的消息内容将消息分发给不同的消费者的场景。
- 主题模式(Topic Mode):主题模式是路由模式的扩展,它允许使用通配符匹配路由键。生产者发送带有特定主题的消息到交换器,消费者可以使用通配符模式订阅特定的主题,只接收与订阅主题匹配的消息。适用于根据复杂的主题匹配规则进行灵活消息过滤和路由的场景。
常用的消息队列中间件
RocketMQ-Erlang语言
RocketMQ-阿里 Java语言,设计时参考了Kafka,消息可靠性上比Kafka更好
ActiveMQ-Apache
Kafka
八. 任务管理
cron时间表达式
1 | {Seconds} {Minutes} {Hours} {DayofMonth} {Month} {DayofWeek} {Year}或 |
九. Java EE后端分层设计
MVC设计模式流程
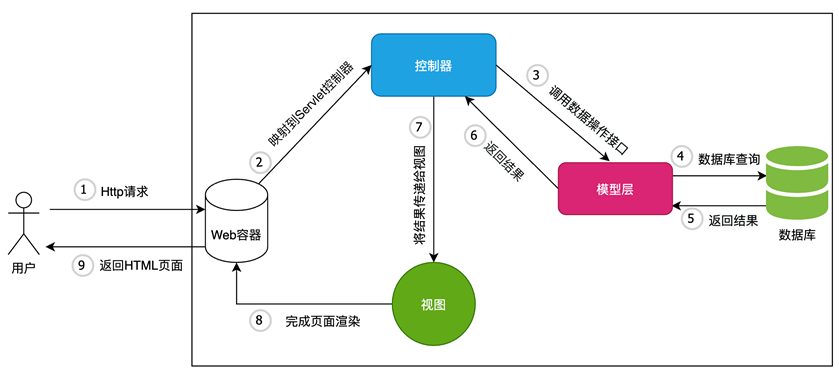
(1)用户发起HTTP请求;
(2)Web服务器接收到请求后,根据请求的url地址将请求转发到相应的servlet进行处理。注意:控制器是和用户交互的接口;
(3)Servlet获取用户请求的相关参数,并根据用户的请求调用模型层相应操作接口;
(4)模型层调用数据库查询接口,进行数据查询;
(5)数据库返回相关的查询结果;
(6)模型层对相应的查询结果进行处理,并返回给控制器;
(7)控制器将封装好的查询结果传递给视图页面;
(8)视图页面获取查询结果,并进行页面渲染输出。
前后端分离模式特点,和传统后端渲染模式的区别
前后端分离模式和传统后端渲染模式是两种不同的架构方式,它们有以下特点和区别:
前后端分离模式的特点:
- 前后端分离:前后端分离模式将前端和后端开发分离,前端负责用户界面和交互逻辑,后端负责数据处理和业务逻辑。
- API通信:前后端通过API进行通信,前端通过调用后端提供的API来获取数据和执行业务逻辑。
- 前端框架:前后端分离模式通常使用前端框架(如React、Angular、Vue.js)来构建交互式用户界面。
- 前端渲染:前端负责将获取到的数据进行渲染和展示,可以通过AJAX或Fetch等技术从后端异步获取数据,并使用JavaScript在客户端进行渲染。
传统后端渲染模式的特点:
- 后端渲染:传统后端渲染模式是指后端负责渲染生成完整的HTML页面,并将页面直接发送给客户端浏览器进行展示。
- 页面刷新:在传统后端渲染模式下,当用户与页面交互或请求新的内容时,通常需要进行整个页面的刷新,后端重新渲染页面并返回给客户端。
- 多页面应用:传统后端渲染模式通常适用于多页面应用(Multi-Page Application,MPA),每个页面由后端负责生成和渲染。
- 服务器负担:由于后端需要处理页面的渲染和请求响应,服务器的负担较重。
区别:
- 前后端分离模式将前端和后端分开,前端负责渲染和交互逻辑,后端提供API和数据服务;传统后端渲染模式中后端负责渲染生成完整的HTML页面。
- 前后端分离模式通过API进行通信,实现异步数据交互,只更新部分页面内容;传统后端渲染模式需要进行整个页面的刷新,导致网络开销较大。
- 前后端分离模式使用前端框架构建交互式用户界面,页面渲染由前端处理;传统后端渲染模式页面渲染由后端负责。
- 前后端分离模式适用于单页面应用(Single-Page Application,SPA)和多页面应用(Multi-Page Application,MPA);传统后端渲染模式主要适用于MPA。
前后端分离模式具有更好的灵活性和可维护性,前后端开发团队可以独立进行工作,并且前端可以使用现代化的技术栈构建交互式的用户界面。传统后端渲染模式在某些情况下可能更适用,特别是对于较为传统的多页面应用。选择哪种模式取决于具体的项目需求和技术栈。
@Service、@Transactional
@Service和@Transactional是Spring框架中的注解,用于在应用程序中提供特定的功能和行为。
@Service注解:@Service注解标记一个类为服务层组件,表示该类用于处理业务逻辑。它通常与@Autowired注解一起使用,将服务类对象注入到其他组件中。@Service注解帮助组织代码,使得代码结构更加清晰,并且方便进行依赖注入和组件扫描。
@Transactional注解:@Transactional注解用于控制事务的行为,用于确保在方法执行期间的数据库操作要么完全成功,要么完全失败(回滚)。它可以在方法级别或类级别上使用。当一个方法或类被标记为@Transactional时,Spring会创建一个事务边界,并确保在方法执行期间的数据库操作遵循事务的ACID特性(原子性、一致性、隔离性和持久性)。
@Transactional注解提供了以下功能:
- 自动地创建和管理事务。
- 当方法执行时,会自动启动事务,并在方法结束时提交事务或回滚事务(根据方法的执行结果)。
- 可以设置事务的隔离级别、传播行为、只读属性等。
使用@Transactional注解可以确保数据库操作的一致性和完整性,并简化了事务管理的代码。它在与持久层框架(如Spring Data JPA、Hibernate)一起使用时,可以自动处理数据库事务,减少手动事务管理的工作量。
设计的基本概念DTO、VO的作用
DTO(Data Transfer Object)和VO(Value Object)是常见的设计模式,用于在不同层之间传输数据和封装数据。
DTO(数据传输对象):
- DTO用于在不同层(如应用层、业务层和表示层)之间传输数据,通常用于解耦和减少网络通信的数据量。
- DTO对象通常是轻量级的,只包含数据的属性以及相应的getter和setter方法,不包含业务逻辑。
- DTO对象可以根据业务需求来定义,用于将多个相关的数据字段封装在一个对象中,方便传输和处理。
VO(值对象):
- VO用于封装特定领域的数据,通常是从业务层中获取的数据,并用于表示层(如UI层)展示数据。
- VO对象包含多个属性,代表一个完整的值,可以是单个值或一组相关值的组合。
- VO对象通常是不可变的,即一旦创建就不能修改其内部状态。
- VO对象可以根据业务需求来定义,用于封装和展示特定领域的数据,方便在表示层进行显示和操作。
作用:
- 解耦和数据传输:DTO和VO可以帮助解耦和不同层之间的数据传输,将数据从一个层传递到另一个层时,可以使用DTO或VO对象来封装数据,避免直接传递大量的数据对象或领域对象。
- 数据封装和展示:DTO和VO提供了一种封装数据的方式,可以将相关的数据字段组合成一个对象,方便传输和展示。VO对象还可以在表示层中用于展示数据,并提供一个统一的视图对象。
- 安全性和灵活性:DTO和VO对象可以根据业务需求定义,仅包含需要传输或展示的属性,可以控制数据的安全性和灵活性。
- 减少网络通信开销:通过使用DTO对象,可以减少网络通信的数据量,只传输必要的数据字段,提高系统性能和效率。
总而言之,DTO和VO是在不同层之间传输和封装数据的对象,可以提高系统的灵活性、性能和安全性,同时帮助解耦不同层的依赖关系。
十. SpringSecurity
在Spring Security中,默认的角色值必须带有”ROLE_”前缀。这是因为Spring Security在进行授权时,会自动在配置的角色前面添加”ROLE_”前缀来与用户的角色进行匹配。
1.SpringSecurity 的两大功能
- 认证(Authentication):Spring Security提供了一系列的身份验证功能,用于验证用户的身份。这包括基于表单登录、基于HTTP基本认证、基于LDAP认证等多种认证方式。Spring Security可以处理用户的认证请求,验证其身份,并提供相应的机制来管理用户的凭证和身份信息。
- 授权(Authorization):Spring Security提供了强大的授权功能,用于管理和控制用户对资源的访问权限。通过配置安全规则和访问控制策略,可以限制特定用户或角色对应用程序中受保护资源的访问。Spring Security支持基于角色的访问控制、基于表达式的访问控制、注解驱动的访问控制等多种授权方式。
2.认证和授权涉及到哪些数据
认证和授权涉及到以下数据:
用户凭证:认证涉及用户凭证的验证,包括用户名、密码、证书或其他身份验证凭证。这些凭证用于验证用户的身份。
用户身份信息:认证过程中需要访问和验证用户的身份信息,例如用户的角色、权限、个人信息等。
访问令牌(Access Token):在一些身份验证流程中,认证成功后会生成访问令牌,该令牌用于后续的请求中进行身份验证和授权。访问令牌包含了用户的身份信息或其他相关信息,用于验证用户的权限和访问权限。
资源和操作:授权涉及到对资源(如网页、API端点、文件等)和操作(如读取、写入、删除等)的权限管理。授权规则确定了哪些用户或用户组有权访问特定的资源和执行特定的操作。
安全规则和配置:认证和授权涉及到安全规则和配置的定义。这些规则定义了身份验证的方式、授权策略、访问控制规则等。安全规则和配置用于指定如何验证用户身份和授予访问权限。
以上数据在认证和授权的过程中起着重要的作用,帮助确保用户的身份验证和对资源的授权是正确且安全的。
3.用户-角色-权限是什么关系?怎么设计数据表
用户-角色-权限是一种常见的权限管理模型,用于管理用户与其对应的角色和权限之间的关系。
在这种模型中,用户(User)是系统中的具体用户实体,每个用户可以被分配一个或多个角色。角色(Role)表示一组权限的集合,可以用来定义用户所拥有的访问权限。权限(Permission)表示对系统中特定资源或操作的访问权限。
设计数据表来支持用户-角色-权限模型时,可以考虑以下几个表:
用户表(User table):包含用户的基本信息,如用户ID、用户名、密码等。
角色表(Role table):包含角色的信息,如角色ID、角色名称等。
权限表(Permission table):包含权限的信息,如权限ID、权限名称、资源路径等。
用户角色关联表(User-Role table):用于建立用户与角色之间的多对多关系。可以包含用户ID和角色ID作为外键,表示用户所拥有的角色。
角色权限关联表(Role-Permission table):用于建立角色与权限之间的多对多关系。可以包含角色ID和权限ID作为外键,表示角色所拥有的权限。
这样的数据表设计模型可以使得用户、角色和权限之间的关系清晰,并支持灵活的权限管理。通过在用户表和角色表之间建立关联,可以将角色分配给用户。同时,通过在角色表和权限表之间建立关联,可以定义角色所拥有的权限。
在实际应用中,根据具体的需求,可能还需要考虑其他表和字段的设计,例如资源表、角色继承关系等。数据表的设计应根据具体的业务需求和系统设计进行调整,以满足系统的权限管理和安全需求。
4.springsecurity 中,角色和权限有哪些区别
在Spring Security中,角色(Role)和权限(Permission)有以下区别:
角色(Role):角色代表一组权限的集合,用于对用户进行分类和授权。角色是对权限的逻辑分组,可以将具有相似权限需求的用户分配到相应的角色中。例如,一个系统可以定义角色为”ADMIN”(管理员)、”USER”(普通用户)等。
权限(Permission):权限代表对系统中特定资源或操作的访问权限。权限是具体的授权单元,表示用户对特定资源或操作的访问权限。例如,一个系统可以定义权限为”READ_USER”(读取用户信息)、”WRITE_USER”(修改用户信息)等。
区别总结:
- 角色是对权限的逻辑分组,用于对用户进行分类和授权。
- 权限是具体的授权单元,表示用户对特定资源或操作的访问权限。
- 角色可以包含多个权限,一个用户可以分配多个角色。
- 权限是最小的授权单元,可以直接分配给用户或包含在角色中。
在Spring Security中,可以使用角色和权限来进行访问控制和权限管理。角色通常在用户和权限之间建立逻辑关联,以简化权限的管理和授权过程。同时,可以使用基于角色或基于权限的访问控制策略来控制用户对资源的访问权限。